[Home] [Puzzles & Projects] [Delphi Techniques] [Math topics] [Library] [Utilities]
|
[Home] [Puzzles & Projects] [Delphi Techniques] [Math topics] [Library] [Utilities]
|
|
Solution spaces for puzzles and games are often represented as graphs. The nodes, or vertices, are valid board configurations and the edges represent moves from one board to another. Consider the game of tic-tac-toe for example. We can assign X,O,or E (empty) to each of the 9 playing positions and represent any board configuration as a string of 9 of these characters (XEEEEEEEE represents player1 placing an X in the upper left corner). The maximum number of nodes is 39, but many of these are invalid. It is an interesting problem to calculate the number of nodes for a graph of TicTacToe and a program TicTacToeCount which does this is included in the download. According to my count, there are slightly more than 6000 valid board positions. There are many more practical applications of graphs but for our purposes puzzles will do. Complete graphs are only feasible for relatively small problems - another example is the Sliding Coins puzzle. A program allowing users to solve the puzzle has already been posted in the Programs section of this site. In this article, we'll explore the theory and provide a program that finds solutions to the Sliding Coins puzzle by searching. First let's figure out how to represent the puzzle in graph form. One common technique is an Adjacency Matrix or Edge matrix. If a graph with N nodes is written as an N x N matrix, the intersection of each row and column can flag existence of an edge between them, or contain a value representing the length (or cost) of the edge (or move). The Edge Matrix reserves space for an edge between any two nodes. If the number of actual edges is small then, a lot of space is wasted. This is typically the case with board puzzles - from any given configuration, only a few positions can be reached on the next move. For these cases, an good alternative data structure is the Adjacency List. Here we make a single master list of all nodes. Each entry in the list will contain the identifier of the node, and a list with pointers to all adjacent nodes. This is the model we'll be using here.
For our master list of all nodes in Delphi we use a TStringlist derivative named TGraphList. It has the advantage of flexibility - the keys identifying our nodes will be strings which can have unlimited length. We can easily sort the resulting list, this allows efficient retrieval with the Find method. Find uses a binary search to retrieve members from a sorted list. And a Stringlist has an Objects property to hold the nodes. The nodes themselves are represented in a TNode container object with lists of pointers to adjacent nodes. We'll investigate 2 techniques to search this structure: depth first search and breadth first search. Each has its advantages and disadvantages. Depth first is fast if we limit the depth, but short solutions are not necessarily found first. Breadth first will always find the minimum length path first, but it's run time can get very long. The routines described here differ from the standard depth-first and breadth-first traversing routines found in texts, Those routines typically are concerned with visiting all nodes in a certain order, not in finding paths from A to B. Depth first follows a node downward to its 1st adjacent node, then to the 1st adjacent node of that one, until something stops the search. We'll then backtrack and follow next adjacent of the predecessor, etc. This is a naturally recursive operation since for each node we need to perform exactly the same operation each of its adjacents. We'll use a logical stack where retrieval always returns the most recent addition to the list (called last In, first out, LIFO retrieval). Here is the pseudocode for depth first search: SearchGoalDF(nodenbr, goalkey, maxdepth) - search depth first for all solutions from nodenbr node to goalkey node with depth of maxdepth or less.
dfs
Notice that if A is adjacent to B, the B is normally also adjacent to A and we must handle the case where we would loop from A to B to A to B, etc. We prevent this with a Visited array that has a flag set when we visit a node so that we do not revisit it while searching down this path. When we backtrack we "unvisit" the node because the next path found may want to include this node also. The something that finally stops the search may be visiting all of the nodes, or some preset limit of how far to search, or a target node and no more paths are needed. This last stopping method is not implemented here, but could be used for a "find any path" scenario. The breadth first search uses a queue list structure where each retrieval returns the node that has been on the queue the longest (first in, first out - FIFO retrieval). The effect of this is to process all nodes adjacent the start node before we process the nodes adjacent to those nodes, etc. We have a new problem introduced by breadth first searching - when we finally get the goal node, we have no idea of how we got there! In the depth first search, each addition was the next node processed and the stack was the path for each solution found. For breadth first, we just throw those adjacents onto the queue to be visited some time later. We'll solve this problem by introducing a new TBreadthObj than contains the node and the path that got us there. These objects will become the queue objects as we search. Pseudocode looks like this: SearchGoalBF(nodenbr, goalkey, maxdepth) - search breadth first for all solutions from nodenbr node to goalkey node of length maxdepth or less.
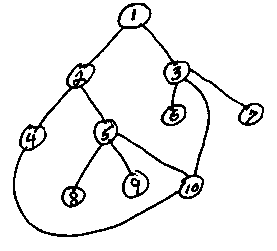
This logic has been incorporated into TGraphList in a unit named UTGraphSearch. Two sample programs are included , one, SimpleSearch, builds a graph with the 10 nodes and 11 edges described above, and searches for ways to get from node #1 to node #10. The second program, CoinSearch, searches for solutions to the Sliding Coin puzzle. Addendum: October 27, 20005: UTGraphSearch has been add to our common DFF Library file, so a one-time download of the current library version (DFFLIBV04 or later) is required to compile the test programs described here. Although not used here, there are several changes to UTGraphSearch in preparation for interactive applications:
Download and Explore
|
[Feedback] [Newsletters (subscribe/view)] [About me]Copyright © 2000-2018, Gary Darby All rights reserved. |